SummarizedBenchmark: Class Details
Patrick K. Kimes, Alejandro Reyes
22 June 2019
Source:vignettes/SummarizedBenchmark-ClassDetails.Rmd
SummarizedBenchmark-ClassDetails.RmdAbstract
“TheSummarizedBenchmark package is built on two primary classes, the BenchDesign class for organizing the design of a benchmark experiment, and the SummarizedExperiment class for organizing the benchmark results. This vignette first introduces the structure and features of these classes using the example benchmark of p-value correction methods described in the SummarizedBenchark: Introduction vignette. Then, some issues of reproduciblity are discussed, and finally, several features and non-standard uses of the classes are described. SummarizedBenchmark package version: 2.3.4”
Introduction
This vignette assumes that the user is familiar with the basics of the SummarizedBenchmark framework for benchmarking computational methods described in the SummarizedBenchmark: Introduction vignette (the “introduction”). New users should start from the package description and example presented in the introduction before moving on to more advanced topics, including the class descriptions in this vignette. Here, we describe the anatomy of the BenchDesign and SummarizedBenchmark classes in a little more detail than was presented in the introduction.
Example Case Study
The classes are described in more detail using the same example benchmark of methods for multiple comparisons adjustment described in the introduction. Briefly, three methods, the Bonferroni correction, Benjamini-Hochberg step-up procedure, and Storey’s FDR q-value were benchmarked on a collection of 50 simulated two-sample t-tests. The simulated t-test results which serve as inputs to the methods are included with the package in the tdat data set.
data(tdat)
b <- BenchDesign(data = tdat) %>%
addMethod(label = "bonf", func = p.adjust,
params = rlang::quos(p = pval, method = "bonferroni")) %>%
addMethod(label = "BH",
func = p.adjust,
params = rlang::quos(p = pval, method = "BH")) %>%
addMethod(label = "qv",
func = qvalue::qvalue,
params = rlang::quos(p = pval),
post = function(x) { x$qvalues })
sb <- buildBench(b, truthCols = "H")The code above is identical to what was used in the introduction to construct the BenchDesign, b, and the SummarizedBenchmark results, sb. If any of this is unclear, consider revisting the SummarizedBenchmark: Introduction vignette.
BenchDesign
BenchDesign objects are composed of a data set and methods. Formally, the methods are stored in the BenchDesign as a BDMethodList and the data as a BDData object. As would be expected, the BDMethodList is a list (List) of BDMethod objects, each containing the definition of a method to be compared in the benchmark experiment. The general structure is illustrated in the figure below.
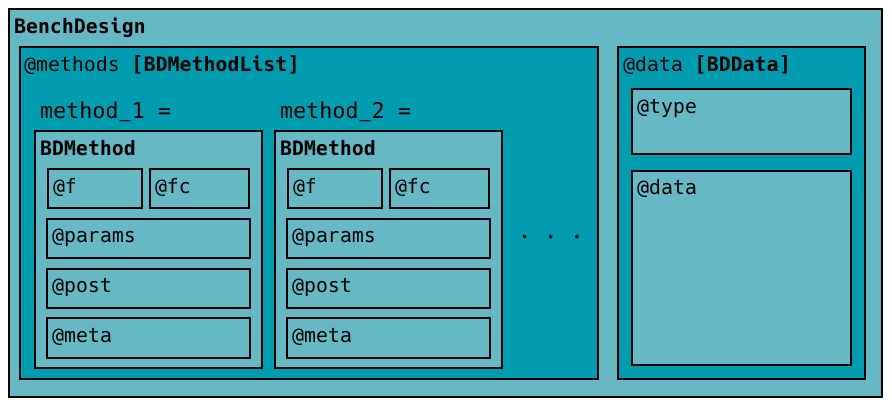
BenchDesign class structure
Continuing with the BenchDesign constructed above, we can access the list of methods and the data set stored in the object using the BDMethodList() and BDData() functions.
## BenchDesign Method List (BDMethodList) ---------------------
## list of 3 methods
## method: bonf; func: p.adjust
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue## BenchDesign Data (BDData) ----------------------------------
## type: data
## data:
## H test_statistic effect_size pval SE
## 1 1 -3.2083437 -1.17151466 4.872282e-03 0.3651463
## 2 0 0.1692236 0.07321912 8.675080e-01 0.4326768
## 3 1 -5.7077940 -1.81715381 2.061521e-05 0.3183636
## 4 1 -1.9805856 -1.09107836 6.313031e-02 0.5508867
## 5 1 -1.0014358 -0.37726058 3.298895e-01 0.3767197
## 6 1 -0.9190433 -0.47583669 3.702252e-01 0.5177522
## 7 1 -1.3184486 -0.72750221 2.038846e-01 0.5517866
## 8 1 -3.8492346 -1.47787871 1.175116e-03 0.3839409
## 9 1 -3.4836213 -1.35474550 2.651401e-03 0.3888900
## 10 0 0.6238195 0.25470364 5.405719e-01 0.4082970
## ... with 30 more rows.BDMethod and BDMethodList
The list of methods inherits from the SimpleList class, and supports several useful accessor and setter features.
## BenchDesign Method (BDMethod) ------------------------------
## method: p.adjust
## function (p, method = p.adjust.methods, n = length(p)...
## parameters:
## p : pval
## method : "bonferroni"
## post:
## none
## meta:
## noneThis interface allows for adding new methods by creating a new named entry in the BDMethodList of the BenchDesign object.
## BenchDesign ------------------------------------------------
## benchmark data:
## type: data
## names: H, test_statistic, effect_size, pval, SE
## benchmark methods:
## method: bonf; func: p.adjust
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue
## method: bonf2; func: p.adjustMethods can also be removed by setting the list value to NULL. An equivalent convenience function, dropMethod() also exists for removing methods using syntax similar to addMethod().
## BenchDesign ------------------------------------------------
## benchmark data:
## type: data
## names: H, test_statistic, effect_size, pval, SE
## benchmark methods:
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue
## method: bonf2; func: p.adjustEach BDMethod object in a BDMethodList encapsulates a method to be benchmarked. The contents of the object are all of the arguments passed through the addMethod() convenience function used in the example above. New BDMethod objects can be constructed directly using the BDMethod() constructor, which takes the same input parameters as addMethod().
## BenchDesign Method (BDMethod) ------------------------------
## method: p.adjust
## function (p, method = p.adjust.methods, n = length(p)...
## parameters:
## p : pval
## method : "bonferroni"
## post:
## none
## meta:
## noneDirectly modifying the BDMethodList object provides an alternative approach (aside form using addMethod()) to adding methods to a BenchDesign object.
## BenchDesign ------------------------------------------------
## benchmark data:
## type: data
## names: H, test_statistic, effect_size, pval, SE
## benchmark methods:
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue
## method: bonf2; func: p.adjust
## method: bonf; func: p.adjustBDData
The BDData object is a simple object which only contains two slots, @type and @data. The @type of a BDData object can be either data or hash. If the @type is data, the @data slot is a standard list or data.frame object of raw data. However, if the @type is hash, then the @data slot is just a MD5 hash of some raw data object computed using digest::digest(). As described next in Section @ref(summarizedbenchmark), SummarizedBenchmark objects also contain the BenchDesign object used to generate the benchmark results. Often, the original raw data can be large, and saving the full data set as part of the SummarizedBenchmark object can be undesirable and unnecessary. While the raw data set is needed during the benchmark experiment, by default, the BDData is converted to a MD5 hash beforing stored the BenchDesign as part of a SummarizedBenchmark object. Using this approach, it is still possible to confirm whether a certain data set was used for a benchmarking experiment without having to store copies of the raw data with every SummarizedBenchmark.
Returning to the BenchDesign example from above, the BDData object of a BenchDesign can also be similarly extracted and modified. As with BDMethod objects, the data set may be removed by setting the value to NULL.
## BenchDesign ------------------------------------------------
## benchmark data:
## NULL
## benchmark methods:
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue
## method: bonf2; func: p.adjust
## method: bonf; func: p.adjustA new data set can be constructed using the BDData() function and used to replace the data set in a BenchDesign object.
## BenchDesign ------------------------------------------------
## benchmark data:
## type: data
## names: H, test_statistic, effect_size, pval, SE
## benchmark methods:
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue
## method: bonf2; func: p.adjust
## method: bonf; func: p.adjustThe helper function hashBDData() can be called on either BDData or BenchDesign objects to convert the data to a MD5 hash. By default, this function is called on the BenchDesign object during buildBench() before storing the object in the resulting SummarizedBenchmark.
## BenchDesign ------------------------------------------------
## benchmark data:
## type: md5hash
## MD5 hash: 09867f2696d3178a8f3bc038917042e1
## benchmark methods:
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue
## method: bonf2; func: p.adjust
## method: bonf; func: p.adjustWe drop the "bonf2" method from the object to return to the same set of methods used to generate the SummarizedBenchmark object.
SummarizedBenchmark
As described above, the SummarizedBenchmark class builds on the existing SummarizedExperiment class and Bioconductor infrastructure. By doing so, saved results are tightly linked to metadata. Thus, it is possible, for example, to easily subset the results without losing references to the respective metadata. For example, the code below extracts the data for only the first two methods.
## DataFrame with 2 rows and 6 columns
## func.pkg func.pkg.vers func.pkg.manual param.p param.method
## <character> <character> <logical> <character> <character>
## bonf stats 3.6.0 FALSE pval "bonferroni"
## BH stats 3.6.0 FALSE pval "BH"
## session.idx
## <numeric>
## bonf 1
## BH 1Building on the SummarizedExperiment class, in addition to the slot for performanceMetrics described above, the SummarizedBenchmark class also includes a slot which stores a copy of the BenchDesign object used to generate the results with buildBench(). The BenchDesign can be accessed by simply passing the object to BenchDesign().
## BenchDesign ------------------------------------------------
## benchmark data:
## type: md5hash
## MD5 hash: 09867f2696d3178a8f3bc038917042e1
## benchmark methods:
## method: bonf; func: p.adjust
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalueNotice, however, unlike the original BenchDesign above, the data is stored as a MD5 hash. To prevent bloat when the data set is large, by default, only a MD5 hash computed using digest::digest() is stored with the benchmarking results. This behavior can be changed by setting keepData = TRUE when calling buildBench(), in which case, the complete data set will be stored as part of the BenchDesign and SummarizedBenchmark objects. A simple helper function, compareBDData(), can be used to verify that while the data type may be different between the data originally used to construct the SummarizedBenchmark and the data stored with the SummarizedBenchmark, the referenced data sets are the same (i.e. have matching MD5 hash values).
## $data
## [1] TRUE
##
## $type
## [1] FALSEFinally, information about the R session where the methods were executed is stored in the metadata of the SummarizedBenchmark as an entry in a list called sessions. The package supports rerunning benchmark experiments, and for this purpose, each new session is stored as a new entry in the sessions list. Since this experiment has only been executed once, the list only has a single entry in the sessions list. In addition to storing the session info and list of methods evaluated during the session, the list also keeps track of all parameters in the buildBench() call, i.e. truthCols = "H".
## $methods
## [1] "bonf" "BH" "qv"
##
## $results
## $results$bonf
## $results$bonf$default
## [1] "success"
##
##
## $results$BH
## $results$BH$default
## [1] "success"
##
##
## $results$qv
## $results$qv$default
## [1] "success"
##
##
##
## $parameters
## $parameters$truthCols
## [1] "H"
##
## $parameters$ftCols
## NULL
##
## $parameters$sortIDs
## [1] FALSE
##
## $parameters$keepData
## [1] FALSE
##
## $parameters$catchErrors
## [1] TRUE
##
## $parameters$parallel
## [1] FALSE
##
## $parameters$BPPARAM
## class: MulticoreParam
## bpisup: FALSE; bpnworkers: 2; bptasks: 0; bpjobname: BPJOB
## bplog: FALSE; bpthreshold: INFO; bpstopOnError: TRUE
## bpRNGseed: ; bptimeout: 2592000; bpprogressbar: FALSE
## bpexportglobals: TRUE
## bplogdir: NA
## bpresultdir: NA
## cluster type: FORK
##
##
## $sessionInfo
## ─ Session info ──────────────────────────────────────────────────────────
## setting value
## version R version 3.6.0 (2019-04-26)
## os macOS Mojave 10.14.1
## system x86_64, darwin15.6.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/New_York
## date 2019-06-18
##
## ─ Packages ──────────────────────────────────────────────────────────────
## package * version date lib source
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 3.6.0)
## backports 1.1.4 2019-04-10 [1] CRAN (R 3.6.0)
## Biobase * 2.45.0 2019-05-02 [1] Bioconductor
## BiocGenerics * 0.31.4 2019-06-10 [1] Bioconductor
## BiocManager 1.30.4 2018-11-13 [1] CRAN (R 3.6.0)
## BiocParallel * 1.19.0 2019-05-02 [1] Bioconductor
## BiocStyle * 2.13.2 2019-06-12 [1] Bioconductor
## bitops 1.0-6 2013-08-17 [1] CRAN (R 3.6.0)
## bookdown 0.11 2019-05-28 [1] CRAN (R 3.6.0)
## cli 1.1.0 2019-03-19 [1] CRAN (R 3.6.0)
## codetools 0.2-16 2018-12-24 [2] CRAN (R 3.6.0)
## colorspace 1.4-1 2019-03-18 [1] CRAN (R 3.6.0)
## commonmark 1.7 2018-12-01 [1] CRAN (R 3.6.0)
## crayon * 1.3.4 2017-09-16 [1] CRAN (R 3.6.0)
## DelayedArray * 0.11.1 2019-06-16 [1] Bioconductor
## desc 1.2.0 2018-05-01 [1] CRAN (R 3.6.0)
## digest * 0.6.19 2019-05-20 [1] CRAN (R 3.6.0)
## dplyr * 0.8.1 2019-05-14 [1] CRAN (R 3.6.0)
## evaluate 0.14 2019-05-28 [1] CRAN (R 3.6.0)
## fs 1.3.1 2019-05-06 [1] CRAN (R 3.6.0)
## GenomeInfoDb * 1.21.1 2019-05-16 [1] Bioconductor
## GenomeInfoDbData 1.2.1 2019-06-17 [1] Bioconductor
## GenomicRanges * 1.37.11 2019-06-11 [1] Bioconductor
## ggplot2 * 3.2.0 2019-06-16 [1] CRAN (R 3.6.0)
## glue 1.3.1 2019-03-12 [1] CRAN (R 3.6.0)
## gridExtra 2.3 2017-09-09 [1] CRAN (R 3.6.0)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 3.6.0)
## htmltools 0.3.6 2017-04-28 [1] CRAN (R 3.6.0)
## IRanges * 2.19.10 2019-06-11 [1] Bioconductor
## knitr 1.23 2019-05-18 [1] CRAN (R 3.6.0)
## lattice 0.20-38 2018-11-04 [2] CRAN (R 3.6.0)
## lazyeval 0.2.2 2019-03-15 [1] CRAN (R 3.6.0)
## magrittr * 1.5 2014-11-22 [1] CRAN (R 3.6.0)
## MASS 7.3-51.4 2019-03-31 [2] CRAN (R 3.6.0)
## Matrix 1.2-17 2019-03-22 [2] CRAN (R 3.6.0)
## matrixStats * 0.54.0 2018-07-23 [1] CRAN (R 3.6.0)
## mclust * 5.4.3 2019-03-14 [1] CRAN (R 3.6.0)
## memoise 1.1.0 2017-04-21 [1] CRAN (R 3.6.0)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 3.6.0)
## pillar 1.4.1 2019-05-28 [1] CRAN (R 3.6.0)
## pkgconfig 2.0.2 2018-08-16 [1] CRAN (R 3.6.0)
## pkgdown 1.3.0 2018-12-07 [1] CRAN (R 3.6.0)
## plyr 1.8.4 2016-06-08 [1] CRAN (R 3.6.0)
## purrr 0.3.2 2019-03-15 [1] CRAN (R 3.6.0)
## qvalue 2.17.0 2019-05-02 [1] Bioconductor
## R6 2.4.0 2019-02-14 [1] CRAN (R 3.6.0)
## Rcpp 1.0.1 2019-03-17 [1] CRAN (R 3.6.0)
## RCurl 1.95-4.12 2019-03-04 [1] CRAN (R 3.6.0)
## reshape2 1.4.3 2017-12-11 [1] CRAN (R 3.6.0)
## rlang * 0.3.4 2019-04-07 [1] CRAN (R 3.6.0)
## rmarkdown 1.13 2019-05-22 [1] CRAN (R 3.6.0)
## roxygen2 6.1.1 2018-11-07 [1] CRAN (R 3.6.0)
## rprojroot 1.3-2 2018-01-03 [1] CRAN (R 3.6.0)
## S4Vectors * 0.23.12 2019-06-11 [1] Bioconductor
## scales 1.0.0 2018-08-09 [1] CRAN (R 3.6.0)
## sessioninfo * 1.1.1 2018-11-05 [1] CRAN (R 3.6.0)
## stringi 1.4.3 2019-03-12 [1] CRAN (R 3.6.0)
## stringr * 1.4.0 2019-02-10 [1] CRAN (R 3.6.0)
## SummarizedBenchmark * 2.3.4 2019-06-18 [1] Bioconductor
## SummarizedExperiment * 1.15.3 2019-06-16 [1] Bioconductor
## tibble * 2.1.3 2019-06-06 [1] CRAN (R 3.6.0)
## tidyr * 0.8.3 2019-03-01 [1] CRAN (R 3.6.0)
## tidyselect 0.2.5 2018-10-11 [1] CRAN (R 3.6.0)
## UpSetR * 1.4.0 2019-05-22 [1] CRAN (R 3.6.0)
## withr 2.1.2 2018-03-15 [1] CRAN (R 3.6.0)
## xfun 0.7 2019-05-14 [1] CRAN (R 3.6.0)
## xml2 1.2.0 2018-01-24 [1] CRAN (R 3.6.0)
## XVector 0.25.0 2019-05-02 [1] Bioconductor
## yaml 2.2.0 2018-07-25 [1] CRAN (R 3.6.0)
## zlibbioc 1.31.0 2019-05-02 [1] Bioconductor
##
## [1] /usr/local/RLibDevel
## [2] /Library/Frameworks/R.framework/Versions/3.6/Resources/libraryReproducibility and Replicability
While the BenchDesign and SummarizedBenchmark classes are designed to enable easier reproduction and replication of benchmark experiments, they are not meant to completely replace properly written and documented analyses. If any functions or packages are needed for the methods defined in the BenchDesign, they must be available and sourced or loaded when running (or re-running) the analyses. As an example, suppose we have the following locally defined method, mymethod(), which depends on another locally defined, but unavailable, function, mysubmethod().
mymethod <- function(x) {
mysubmethod(x)
}
mybd <- BenchDesign(data = list(vals = 1:5))
mybd <- addMethod(mybd, "method1", mymethod,
params = rlang::quos(x = vals))The top level mymethod() is captured in the corresponding BDMethod and BenchDesign. No errors are thrown since including mymethod() in a BenchDesign object does not require evaluating the function.
## function(x) {
## mysubmethod(x)
## }However, when buildBench() is called, the method naturally fails because the necessary mysubmethod() is not available in the current session.
## !! error caught in buildBench !!
## !! error in main function of method: 'method1'## !! original message:
## !! could not find function "mysubmethod"## <simpleError in buildBench(mybd):
## No method returned valid values for any assays!
## >Therefore, if any locally defined functions are necessary for a method, they should be available along with the BenchDesign object or defined at the top level. Additionally, for reproducibility and clarity, we generally recommend keeping functions as “self-contained” as possible, and never relying on variables defined externally, e.g. in the global enviroment. Scoping with functions can be confusing, and it may not always be clear where constants are being evaluated. As an example, consider the following simple multiplying function.
m <- 5
mymult <- function(x) {
m * x
}
m <- 2
mybd <- BenchDesign(data = list(vals = 1:5, m = 10))
mybd <- addMethod(mybd, "methodr", mymult,
params = rlang::quos(x = vals))While experienced R programmers may know which value of m (5, 2 or 10) will be used when buildBench() is called, for many users, this is less obvious.
## methodr
## [1,] 2
## [2,] 4
## [3,] 6
## [4,] 8
## [5,] 10The answer is the value assigned most recently in the environment where mymult() was defined, R_GlobalEnv, the global environment (m = 2). Note, however, that if the BenchDesign is saved and reloaded in a new session, whatever value of m is defined in the global environment of the new session will be used. If m is not defined in the new session, an error will be thrown. In this case, m should either be explicitly defined within the function or passed as a second input variable of mymult() and defined with params = in the BDMethod.
While it may be possible to aggressively capture all code and environment variables defined with each method in a BenchDesign, it is not within the scope of this package, and furthermore, may not be the best appraoch to constructing a reproducible benchmark. While redundant, for emphasis, we reiterate that the SummarizedBenchmark framework is a solution for structuring benchmark experiments which complements, but does not replace, well documented and organized code.
BenchDesign Features
Several less prominent, but hopefully useful features are also implemented for working with objects of the BenchDesign, BDMethod, and BDMethodList classes.
Specifying Method Metadata
As seen in the example above, metadata for methods are stored in the colData() of SummarizedBenchmark objects. Several default metadata columns are populated in the colData() of the SummarizedBenchmark object generated by a call to buildBench(). However, sometimes it may be useful to include additional metadata columns beyond just the defaults. While this can be accomplished manually by modifying the colData() of the SummarizedBenchmark object post hoc, method metadata can also be specified at the addMethod() step using the meta = optional parameter. The meta = parameter accepts a named list of metadata information. Each list entry will be added to the colData() as a new column, and should be the same type across methods to prevent possible errors. To avoid collisions between metadata columns specified with meta = and the default set of columns, metadata specified using meta = will be added to colData() with meta. prefixed to the column name.
As an example, we construct a BenchDesign object again using the multiple hypothesis testing example. The BenchDesign is created with two methods, Bonferroni correction and the Benjamini-Hochberg step-up procedure. Each method is specified with the optional meta = parameter noting the type of control provided, either familywise error rate (FWER) or false discovery rate (FDR). We can verify that the manually defined metadata column (meta.type) is available in the colData() of the newly generated SummarizedBenchmark.
b_withmeta <- BenchDesign(data = tdat) %>%
addMethod(label = "bonf", func = p.adjust,
meta = list(type = "FWER control"),
params = rlang::quos(p = pval, method = "bonferroni")) %>%
addMethod(label = "BH",
func = p.adjust,
meta = list(type = "FDR control"),
params = rlang::quos(p = pval, method = "BH"))
sb_withmeta <- buildBench(b_withmeta)
colData(sb_withmeta)## DataFrame with 2 rows and 7 columns
## func.pkg func.pkg.vers func.pkg.manual param.p param.method
## <character> <character> <logical> <character> <character>
## bonf stats 3.6.0 FALSE pval "bonferroni"
## BH stats 3.6.0 FALSE pval "BH"
## meta.type session.idx
## <character> <numeric>
## bonf FWER control 1
## BH FDR control 1While all methods in this example had the meta = option specified, this is not necessary. It is completely acceptable to specify the meta = parameter for only a subset of methods. Missing entries will be recorded as NAs in the colData().
Specifying Version Metadata
Arguably, two of the most important pieces of metadata stored in the colData() of the SummarizedBenchmark returned by buildBench() are the relevant package name and version (pkg_name, pkg_vers). Determining the package name and version requires the primary “workhorse” function of the method be directly specified as func = in the addMethod() call. In some cases, this may not be possible, e.g. if the “workhorse” function is a wrapper. However, there still might exist an important function for which we would like to track the package name and version. The meta parameter can help.
The meta = parameter will handle the following named list entries as special values: pkg_name, pkg_vers, pkg_func. First, if values are specified for pkg_name and pkg_vers in meta =, these will overwrite the values determined from func =. To trace the source of pkg_name and pkg_vers information, the func.pkg.manual column of the colData will be set to TRUE (the default value is FALSE). Alternatively, a function can be passed to meta = as pkg_func. This function will be used to determine both pkg_name and pkg_vers, and will take precendence over manually specified pkg_name and pkg_vers values. If pkg_func is specified, it will be included in the colData() as a new column with the same name, and the vers_src column will be set to "meta_func". **Note: the function should be wrapped in rlang::quo to be properly parsed.
We illustrate the behavior when using either pkg_func or pkg_name and pkg_vers with the meta optional parameter using the same multiple testing example from above. First, notice that Storey’s q-value method was previously included in the BenchDesign with a post = argument to extract q-values from the result of calling qvalue::qvalue on the data.
## qv ---------------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: qvalue::qvalue
## function (p, fdr.level = NULL, pfdr = FALSE, lfdr.out...
## parameters:
## p : pval
## post:
## default : function (x) { ...
## meta:
## noneWe can avoid specifying post = by using the following wrapper function in place of the direct call to qvalue::qvalue.
qv_wrapper <- function(...) {
qvalue::qvalue(...)$qvalues
}
b_qv <- BenchDesign(data = tdat) %>%
addMethod(label = "qv",
func = qvalue::qvalue,
params = rlang::quos(p = pval),
post = function(x) { x$qvalues }) %>%
addMethod(label = "qv_wrapper",
func = qv_wrapper,
params = rlang::quos(p = pval))However, we see that while the results for the two methods are the same, the colData() of the resulting SummarizedBenchmark object is missing the valuable package name and version information for the wrapper-based approach.
## qv qv_wrapper
## [1,] 0.0079813228 0.0079813228
## [2,] 0.3290660527 0.3290660527
## [3,] 0.0003753518 0.0003753518
## [4,] 0.0442094809 0.0442094809
## [5,] 0.1716134119 0.1716134119
## [6,] 0.1757029652 0.1757029652## DataFrame with 2 rows and 5 columns
## func.pkg func.pkg.vers func.pkg.manual param.p
## <character> <character> <logical> <character>
## qv qvalue 2.17.0 FALSE pval
## qv_wrapper NA NA FALSE pval
## session.idx
## <numeric>
## qv 1
## qv_wrapper 1This can be fixed by specifying either the pkg_func or pkg_name and pkg_vers metadata values.
b_qv <- b_qv %>%
addMethod(label = "qv_pkgfunc",
func = qv_wrapper,
meta = list(pkg_func = qvalue::qvalue),
params = rlang::quos(p = pval)) %>%
addMethod(label = "qv_pkgname",
func = qv_wrapper,
meta = list(pkg_name = "qvalue", pkg_vers = as.character(packageVersion("qvalue"))),
params = rlang::quos(p = pval))
sb_qv <- buildBench(b_qv)
colData(sb_qv)## DataFrame with 4 rows and 5 columns
## func.pkg func.pkg.vers func.pkg.manual param.p
## <character> <character> <logical> <character>
## qv qvalue 2.17.0 FALSE pval
## qv_wrapper NA NA FALSE pval
## qv_pkgfunc qvalue 2.17.0 TRUE pval
## qv_pkgname qvalue 2.17.0 TRUE pval
## session.idx
## <numeric>
## qv 1
## qv_wrapper 1
## qv_pkgfunc 1
## qv_pkgname 1The func.pkg and func.pkg.vers columns of the colData() are now populated with the correct information, and furthermore, the func.pkg.manual column is set to TRUE for the two latter methods.
Modifying Methods in a BenchDesign
Modifying the defintion of a method after it has been added to a BenchDesign is supported by the modifyMethod() function. The BenchDesign object created in the multiple testing example above, b, includes a method called qv.
## qv ---------------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: qvalue::qvalue
## function (p, fdr.level = NULL, pfdr = FALSE, lfdr.out...
## parameters:
## p : pval
## post:
## default : function (x) { ...
## meta:
## noneSuppose we wish to specify an additional pi0 = parameter for the qvalue::qvalue method as well as add a new metadata tag. This can be accomplished by passing both new parameters to the params = parameter of modifyMethod() as a rlang::quos(..) list. By default, all entries in the rlang::quos(..) list are assumed to be parameters for the main function of the method. However, func, post, or meta values can also be modified by included in their new values in the list using the special keywords, bd.func =, bd.post =, or bd.meta =. In the example below, we both add a new parameter , pi0 = and modify the meta = specification.
new_params <- rlang::quos(pi0 = 0.9, bd.meta = list(type = "FDR control"))
b_modqv <- modifyMethod(b, label = "qv", params = new_params)
printMethod(b_modqv, "qv")## qv ---------------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: qvalue::qvalue
## function (p, fdr.level = NULL, pfdr = FALSE, lfdr.out...
## parameters:
## p : pval
## pi0 : 0.9
## post:
## default : function (x) { ...
## meta:
## type : "FDR control"We can see that the original method parameters, namely p = pval, is still defined for method, while the new method parameter pi0 = 0.9 has been added along with the new metadata specification. However, sometimes it may be desirable to completely overwrite all function parameters for a method, e.g. if we decide to completely redefine the parameters of a method. This may occur if some parameters were optional and originally specified, but no longer necessary. All function parameters can be overwritten by specifying .overwrite = TRUE.
b_modqv <- modifyMethod(b, label = "qv", params = new_params, .overwrite = TRUE)
printMethod(b_modqv, "qv")## qv ---------------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: qvalue::qvalue
## function (p, fdr.level = NULL, pfdr = FALSE, lfdr.out...
## parameters:
## pi0 : 0.9
## post:
## default : function (x) { ...
## meta:
## type : "FDR control"Now the originally specified p = pval is no longer included in the method definition. Obviously, this is not reasonable in this setting as the p parameter is a necessary parameter to run the method. Note that specifications of bd.meta = will always overwrite the existing metadata values of the method, even when .overwrite = FALSE.
Duplicating Methods in a BenchDesign
In addition to comparing multiple methods, a benchmark study may also involve comparing a single method across several parameter settings. The expandMethod() function provides the capability to take a method already defined in the BenchDesign, and expand it to multiple methods with differing parameter values in the BenchDesign object. In the following example, expandMethod() is used to duplicate the qv method with only the pi0 parameter modified. By default, the expanded method, in this case qv, is dropped. To prevent this from happening, .replace = FALSE can be specified.
Expanding the qv method with expandMethod() is accomplished by specifying any new parameters of the variant methods to params = as a rlang::quos(..) list. Here, two new variants of the qv method, qv-p90 and qv-p10, are created with new values of the pi0 parameter.
b_expand <- expandMethod(b, label = "qv",
params = list(qv_p90 = rlang::quos(pi0 = 0.90),
qv_p10 = rlang::quos(pi0 = 0.10)),
.replace = FALSE)
b_expand## BenchDesign ------------------------------------------------
## benchmark data:
## type: md5hash
## MD5 hash: 09867f2696d3178a8f3bc038917042e1
## benchmark methods:
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue
## method: bonf; func: p.adjust
## method: qv_p90; func: qvalue::qvalue
## method: qv_p10; func: qvalue::qvalue## qv_p90 -----------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: qvalue::qvalue
## function (p, fdr.level = NULL, pfdr = FALSE, lfdr.out...
## parameters:
## p : pval
## pi0 : 0.9
## post:
## default : function (x) { ...
## meta:
## none## qv_p10 -----------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: qvalue::qvalue
## function (p, fdr.level = NULL, pfdr = FALSE, lfdr.out...
## parameters:
## p : pval
## pi0 : 0.1
## post:
## default : function (x) { ...
## meta:
## noneWhen only a single parameter is modifed as in the example above, an alternative shorthand is provided. The parameter can be specified with onlyone = and the corresponding values specified with the new method names to params =.
b_expand <- expandMethod(b, label = "qv", onlyone = "pi0",
params = rlang::quos(qv_p90 = 0.90,
qv_p10 = 0.10),
.replace = FALSE)
b_expand## BenchDesign ------------------------------------------------
## benchmark data:
## type: md5hash
## MD5 hash: 09867f2696d3178a8f3bc038917042e1
## benchmark methods:
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalue
## method: bonf; func: p.adjust
## method: qv_p90; func: qvalue::qvalue
## method: qv_p10; func: qvalue::qvalueThe resulting modified BenchDesign object is the same.
SummarizedBenchmark Features
Aside from the standard SummarizedBenchmark
Manually Constructing
Throughout our documentation, SummarizedBenchmark objects are constructed exclusively using our recommended workflow by running buildBench() with a BenchDesign object. This recommended approach enables users to perform benchmark comparisons while automatically keeping track of parameters and software metadata. However, it is also possible to skip this recommended approach and construct a SummarizedBenchmark object directly from standard S3 data objects.
Using data from the iCOBRApackage (Soneson and Robinson 2016), this part of the vignette demonstrates how to build SummarizedBenchmark objects from S3 objects. The dataset contains differential expression results of three different methods (limma, edgeR and DESeq2) applied to a simulated RNA-seq dataset.
The process of building a SummarizedBenchmark object is similar to the process of constructing a SummarizedExperiment object. To build a SummarizedBenchmark object, three main objects are required: (1) a list where each element corresponds to a data.frame, (2) a DataFrame with annotations of the methods, and (3) when available, a DataFrame of ground truths.
In the SummarizedBenchmark object, each output of the methods is considered a different assay. For example, using the differential expression dataset example, we can define two assays, q-values and estimated log fold changes. For each assay, we arrange the output of the different methods as a matrix where each column corresponds to a method and each row corresponds to each feature (in this case, genes). We will need a list in which each of it’s element corresponds to an assay.
assays <- list(qvalue = cobradata_example@padj,
logFC = cobradata_example@score)
assays[["qvalue"]]$DESeq2 <- p.adjust(cobradata_example@pval$DESeq2, method = "BH")
head(assays[["qvalue"]], 3)## edgeR voom DESeq2
## ENSG00000000457 0.2833295 0.1375146 0.04760152
## ENSG00000000460 0.2700376 0.2826398 0.08717737
## ENSG00000000938 0.9232794 0.9399669 0.99856748## edgeR voom DESeq2
## ENSG00000000457 0.22706080 0.23980596 0.274811698
## ENSG00000000460 0.31050478 0.27677537 0.359226203
## ENSG00000000938 0.04985025 0.03344113 0.001526355Since these are simulated data, the ground truths for both assays are known and available. We can format these as a DataFrame where each column corresponds to an assay and each row corresponds to a feature.
library(S4Vectors)
groundTruth <- DataFrame(cobradata_example@truth[, c("status", "logFC")])
colnames(groundTruth) <- names(assays)
groundTruth <- groundTruth[rownames(assays[[1]]), ]
head(groundTruth)## DataFrame with 6 rows and 2 columns
## qvalue logFC
## <integer> <numeric>
## ENSG00000000457 0 0
## ENSG00000000460 0 0
## ENSG00000000938 0 0
## ENSG00000000971 0 0
## ENSG00000001460 1 3.93942204325368
## ENSG00000001461 1 0.0602244207363294Finally, the method names are also reformatted as a DataFrame of simple annotation data of the methods.
## DataFrame with 3 rows and 1 column
## method
## <character>
## 1 edgeR
## 2 voom
## 3 DESeq2A SummarizedBenchmark is built using the following call to the SummarizedBenchmark() constructor.
Next Steps
This vignette described the structure of the BenchDesign and SummarizedBenchmark classes which underly the SummarizedBenchmark package, as well as several complex and non-standard features of both classes. Examples of using these classes and the SummarizedBenchmark framework can be found in the SummarizedBenchmark: Full Case Study vignette as well as in the other Case Study vignettes. More advanced features are also described in various Feature vignettes.
References
Soneson, Charlotte, and Mark D Robinson. 2016. “iCOBRA: Open, Reproducible, Standardized and Live Method Benchmarking.” Nature Methods 13 (4):283–83. https://doi.org/10.1038/nmeth.3805.