SummarizedBenchmark: Introduction
Patrick K. Kimes, Alejandro Reyes
22 June 2019
Source:vignettes/SummarizedBenchmark-Introduction.Rmd
SummarizedBenchmark-Introduction.RmdAbstract
“When performing a data analysis in R, users are often presented with multiple packages and methods for accomplishing the same task. Benchmarking the performance of these different methods on real and simulated data sets is a common way of learning the relative strengths and weaknesses of each approach. However, as the number of tools and parameters increases, keeping track of output and how it was generated can quickly becomes messy. TheSummarizedBenchmark package provides a framework for organizing benchmark comparisons, making it easier to both reproduce the original benchmark and replicate the comparison with new data. This vignette introduces the general approach and features of the package using a simple example. SummarizedBenchmark package version: 2.3.4”
Introduction
With SummarizedBenchmark, a complete benchmarking workflow is comprised of three primary components:
- data,
- methods, and
- performance metrics.
The first two (data and methods) are necessary for carrying out the benchmark experiment, and the last (performance metrics) is essential for evaluating the results of the experiment. Following this approach, the SummarizedBenchmark package defines two primary types of objects: BenchDesign objects and SummarizedBenchmark objects. BenchDesign objects contain only the design of the benchmark experiment, namely the data and methods, where a method is defined as the combination of a function or algorithm and parameter settings. After constructing a BenchDesign, the experiment is executed to create a SummarizedBenchmark containing the results of applying the methods to the data. SummarizedBenchmark objects extend the Bioconductor SummarizedExperiment class, with the additional capability of working with performance metrics.
The basic framework is illustrated in the figure below. A BenchDesign is created with methods and combined with data to create a SummarizedBenchmark, which contains the output of applying the methods to the data. This output is then paired with performance metrics specified by the user. Note that the same BenchDesign can be combined with several data sets to produce several SummarizedBenchmark objects with the corresponding outputs. For convenience, several default performance metrics are implemented in the package, and can be added to SummarizedBenchmark objects using simple commands.
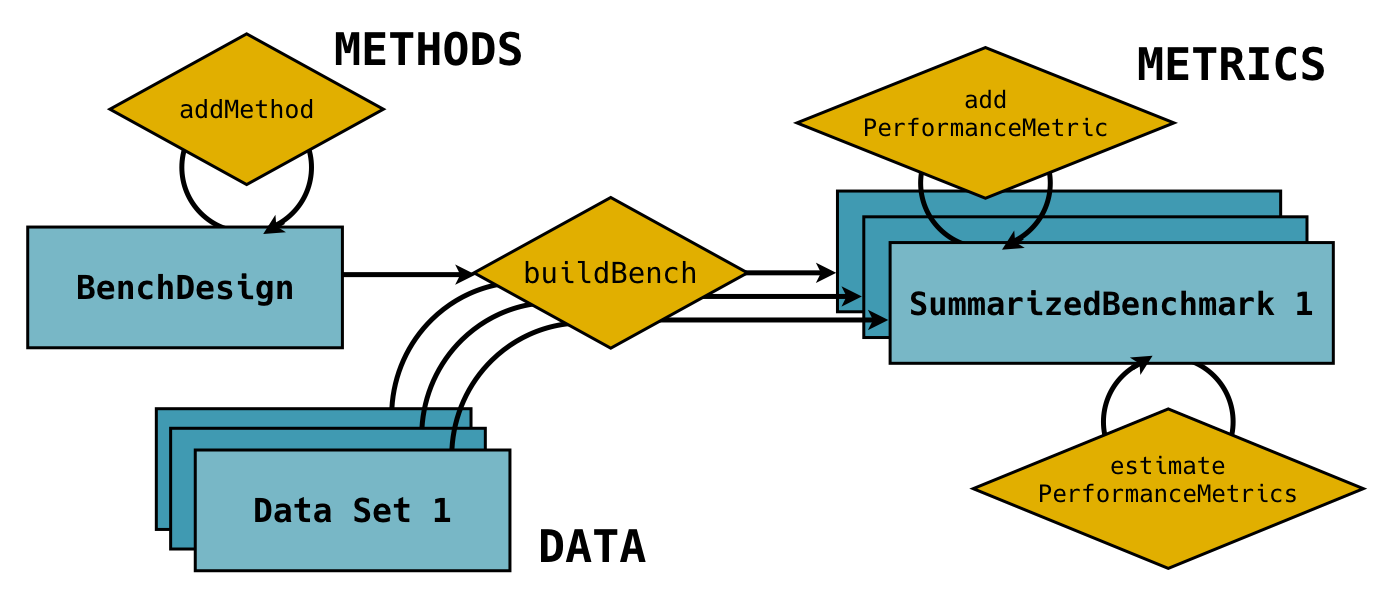
basic benchmarking class relationship
In this vignette, we first illustrate the basic use of both the BenchDesign and SummarizedBenchmark classes with a simple comparison of methods for p-value correction in the context of multiple hypothesis testing. More advanced features of the package are demonstrated in several other case study vignettes. After becoming familiar with the basic SummarizedBenchmark framework described in this introduction, we recommend reading the SummarizedBenchmark: Class Details vignette for more on the structure of the BenchDesign and SummarizedBenchmark classes and details on issues of reproducibility using these classes. Then, we recommend moving on to the more detailed SummarizedBenchmark: Full Case Study vignette where we describe more advanced features of the package with a case study comparing three methods for differential expression analysis.
Quickstart Case Study
To illustrate the basic use of the BenchDesign class, we use the tdat data set included with this package.
The data set is a data.frame containing the results of 50 two-sample t-tests. The tests were performed using independently simulated sets of 20 observations drawn from a single standard Normal distribution (when H = 0) or two mean-shifted Normal distributions (when H = 1).
## H test_statistic effect_size pval SE
## 1 1 -3.2083437 -1.17151466 4.872282e-03 0.3651463
## 2 0 0.1692236 0.07321912 8.675080e-01 0.4326768
## 3 1 -5.7077940 -1.81715381 2.061521e-05 0.3183636
## 4 1 -1.9805856 -1.09107836 6.313031e-02 0.5508867
## 5 1 -1.0014358 -0.37726058 3.298895e-01 0.3767197
## 6 1 -0.9190433 -0.47583669 3.702252e-01 0.5177522Several approaches have been proposed and implemented to compute adjusted p-values and q-values with the goal of controlling the total number of false discoveries across a collection of tests. In this example, we compare three such methods:
- Bonferroni correction (
p.adjustw/method = "bonferroni") (Dunn 1961), - Benjamini-Hochberg (
p.adjustw/method = "BH") (Benjamini and Hochberg 1995), and - Storey’s FDR q-value (
qvalue::qvalue) (Storey 2002).
First, consider how benchmarking the three methods might look without the SummarizedBenchmark framework.
To compare methods, each is applied to tdat, and the results are stored in separate variables.
adj_bonf <- p.adjust(p = tdat$pval, method = "bonferroni")
adj_bh <- p.adjust(p = tdat$pval, method = "BH")
qv <- qvalue::qvalue(p = tdat$pval)
adj_qv <- qv$qvaluesSince the values of interest are available from the ouput of each method as a vector of length 50 (the number of hypotheses tested), to keep things clean, they can be combined into a single data.frame.
## adj_bonf adj_bh adj_qv
## 1 0.24361409 0.02191765 0.0079813228
## 2 1.00000000 0.90365415 0.3290660527
## 3 0.00103076 0.00103076 0.0003753518
## 4 1.00000000 0.12140444 0.0442094809
## 5 1.00000000 0.47127065 0.1716134119
## 6 1.00000000 0.48250104 0.1757029652The data.frame of adjusted p-values and q-values can be used to compare the methods, either by directly parsing the table or using a framework like iCOBRA. Additionally, the data.frame can be saved as a RDS or Rdata object for future reference, eliminating the need for recomputing on the original data.
While this approach can work well for smaller comparisons, it can quickly become overwhelming and unweildy as the number of methods and parameters increases. Furthermore, once each method is applied and the final data.frame (adj) is constructed, there is no way to determine how each value was calculated. While an informative name can be used to “label” each method (as done above), this does not capture the full complexity, e.g. parameters and context, where the function was evaluated. One solution might involve manually recording function calls and parameters in a separate data.frame with the hope of maintaining synchrony with the output data.frame. However, this is prone to errors, e.g. during fast “copy and paste” operations or additions and deletions of parameter combinations. An alternative (and hopefully better) solution, is to use the framework of the SummarizedBenchmark package.
In the SummarizedBenchmark approach, a BenchDesign is constructed with the data and any number of methods. Optionally, a BenchDesign can also be constructed without any data or method inputs. Methods and data can be added or removed from the object modularly in a few different ways, as will be described in the following section. For simplicity, we first show how to construct the BenchDesign with just the data set as input. The data object, here tdat, must be passed explicitly to the data = parameter.
Then, each method of interest can be added to the BenchDesign using addMethod().
b <- addMethod(bd = b, label = "bonf", func = p.adjust,
params = rlang::quos(p = pval, method = "bonferroni"))At a minimum, addMethod() requires three parameters:
-
bd: the BenchDesign object to modify, -
label: a character name for the method, and -
func: the function to be called.
After the minimum parameters are specified, any parameters needed by the func method should be passed as named parameters, e.g. p = pval, method = "bonferroni", to params = as a list of quosures using rlang::quos(..). Notice here that the pval wrapped in rlang::quos(..) does not need to be specified as tdat$pval for the function to access the column in the data.frame. For readers familiar with the ggplot2 package, the use of params = rlang::quos(..) here should be viewed similar to the use of aes = aes(..) in ggplot2 for mapping between the data and plotting (or benchmarking) parameters.
The process of adding methods can be written more concisely using the pipe operators from the magrittr package.
b <- b %>%
addMethod(label = "BH",
func = p.adjust,
params = rlang::quos(p = pval, method = "BH")) %>%
addMethod(label = "qv",
func = qvalue::qvalue,
params = rlang::quos(p = pval),
post = function(x) { x$qvalues })For some methods, such as the q-value approach above, it may be necessary to call a “post-processing” function on the primary method to extract the desired output (here, the q-values). This should be specified using the optional post = parameter.
Now, the BenchDesign object contains three methods. This can be verified either by calling on the object.
## BenchDesign ------------------------------------------------
## benchmark data:
## type: data
## names: H, test_statistic, effect_size, pval, SE
## benchmark methods:
## method: bonf; func: p.adjust
## method: BH; func: p.adjust
## method: qv; func: qvalue::qvalueMore details about each method can be seen by using the printMethods() function.
## bonf -------------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: p.adjust
## function (p, method = p.adjust.methods, n = length(p)...
## parameters:
## p : pval
## method : "bonferroni"
## post:
## none
## meta:
## none
## BH ---------------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: p.adjust
## function (p, method = p.adjust.methods, n = length(p)...
## parameters:
## p : pval
## method : "BH"
## post:
## none
## meta:
## none
## qv ---------------------------------------------------------
## BenchDesign Method (BDMethod) ------------------------------
## method: qvalue::qvalue
## function (p, fdr.level = NULL, pfdr = FALSE, lfdr.out...
## parameters:
## p : pval
## post:
## default : function (x) { ...
## meta:
## noneWhile the bench now includes all the information necessary for performing the benchmarking study, the actual adjusted p-values and q-values have not yet been calculated. To do this, we simply call buildBench(). While buildBench() does not require any inputs other than the BenchDesign object, when the corresponding ground truth is known, the truthCols = parameter should be specified. In this example, the H column of the tdat data.frame contains the true null or alternative status of each simulated hypothesis test. Note that if any of the methods are defined in a separate package, they must be installed and loaded before running the experiment.
The returned object is a SummarizedBenchmark class. The SummarizedBenchmark object is an extension of a SummarizedExperiment object. The table of adjusted p-values and q-values is contained in a single “assay” of the object with each method added using addMethod() as a column with the corresponding label as the name.
## bonf BH qv
## [1,] 0.24361409 0.02191765 0.0079813228
## [2,] 1.00000000 0.90365415 0.3290660527
## [3,] 0.00103076 0.00103076 0.0003753518
## [4,] 1.00000000 0.12140444 0.0442094809
## [5,] 1.00000000 0.47127065 0.1716134119
## [6,] 1.00000000 0.48250104 0.1757029652Metadata for the methods is contained in the colData() of the same object, with each row corresponding to one method in the comparison.
## DataFrame with 3 rows and 6 columns
## func.pkg func.pkg.vers func.pkg.manual param.p param.method
## <character> <character> <logical> <character> <character>
## bonf stats 3.6.0 FALSE pval "bonferroni"
## BH stats 3.6.0 FALSE pval "BH"
## qv qvalue 2.17.0 FALSE pval NA
## session.idx
## <numeric>
## bonf 1
## BH 1
## qv 1In addition to columns for the functions and parameters specified with addMethod() (func, post, label, param.*), the colData() includes several other columns added during the buildBench() process. Most notably, columns for the package name and version of func if available (func.pkg, func.pkg.vers).
When available, ground truth data is contained in the rowData() of the SummarizedBenchmark object.
## DataFrame with 50 rows and 1 column
## H
## <numeric>
## 1 1
## 2 0
## 3 1
## 4 1
## 5 1
## ... ...
## 46 0
## 47 1
## 48 0
## 49 1
## 50 1In addition, the SummarizedBenchmark class contains an additional slot where users can define performance metrics to evaluate the different methods. Since different benchmarking experiments may require the use of different metrics to evaluate the performance of the methods, the SummarizedBenchmark class provides a flexible way to define performance metrics. We can define performance metrics using the function addPerformanceMetric() by providing a SummarizedBenchmark object, a name of the metric, an assay name, and the function that defines it. Importantly, the function must contain the following two arguments: query (referring to a vector of values being evaluated, i.e. the output of one method) and truth (referring to the vector of ground truths). If further arguments are provided to the performance function, these must contain default values.
For our example, we define the performance metric “TPR” (True Positive Rate) that calculates the fraction of true positives recovered given an alpha value. This performance metric uses the H assay of our SummarizedBenchmark example object.
sb <- addPerformanceMetric(
object = sb,
assay = "H",
evalMetric = "TPR",
evalFunction = function(query, truth, alpha = 0.1) {
goodHits <- sum((query < alpha) & truth == 1)
goodHits / sum(truth == 1)
}
)
performanceMetrics(sb)[["H"]]## $TPR
## function(query, truth, alpha = 0.1) {
## goodHits <- sum((query < alpha) & truth == 1)
## goodHits / sum(truth == 1)
## }Having defined all the desired performance metrics, the function estimatePerformanceMetrics() calculates these for each method. Parameters for the performance functions can be passed here. In the case below, we specify several alpha = values to be used for calculating the performance metrics with each function.
## DataFrame with 3 rows and 9 columns
## func.pkg func.pkg.vers func.pkg.manual param.p param.method
## <character> <character> <logical> <character> <character>
## bonf stats 3.6.0 FALSE pval "bonferroni"
## BH stats 3.6.0 FALSE pval "BH"
## qv qvalue 2.17.0 FALSE pval NA
## session.idx TPR.1 TPR.2 TPR.3
## <numeric> <numeric> <numeric> <numeric>
## bonf 1 0.125 0.2 0.225
## BH 1 0.375 0.55 0.625
## qv 1 0.6 0.7 0.9By default, the function above returns a DataFrame, where the parameters of the performance function are stored in its elementMetadata().
## DataFrame with 9 rows and 4 columns
## colType assay performanceMetric alpha
## <character> <character> <character> <numeric>
## func.pkg methodInformation NA NA NA
## func.pkg.vers methodInformation NA NA NA
## func.pkg.manual methodInformation NA NA NA
## param.p methodInformation NA NA NA
## param.method methodInformation NA NA NA
## session.idx methodInformation NA NA NA
## TPR.1 performanceMetric H TPR 0.05
## TPR.2 performanceMetric H TPR 0.1
## TPR.3 performanceMetric H TPR 0.2A second possibility is to set the parameter addColData = TRUE for these results to be stored in the colData() of the SummarizedBenchmark object.
## DataFrame with 3 rows and 10 columns
## func.pkg func.pkg.vers func.pkg.manual param.p param.method
## <character> <character> <logical> <character> <character>
## bonf stats 3.6.0 FALSE pval "bonferroni"
## BH stats 3.6.0 FALSE pval "BH"
## qv qvalue 2.17.0 FALSE pval NA
## session.idx TPR.1 TPR.2 TPR.3 pm.session
## <numeric> <numeric> <numeric> <numeric> <numeric>
## bonf 1 0.125 0.2 0.225 1
## BH 1 0.375 0.55 0.625 1
## qv 1 0.6 0.7 0.9 1## DataFrame with 10 rows and 4 columns
## colType assay performanceMetric
## <character> <character> <character>
## func.pkg methodInformation NA NA
## func.pkg.vers methodInformation NA NA
## func.pkg.manual methodInformation NA NA
## param.p methodInformation NA NA
## param.method methodInformation NA NA
## session.idx methodInformation NA NA
## TPR.1 performanceMetric H TPR
## TPR.2 performanceMetric H TPR
## TPR.3 performanceMetric H TPR
## pm.session performanceMetricSession NA NA
## alpha
## <numeric>
## func.pkg NA
## func.pkg.vers NA
## func.pkg.manual NA
## param.p NA
## param.method NA
## session.idx NA
## TPR.1 0.05
## TPR.2 0.1
## TPR.3 0.2
## pm.session NAFinally, if the user prefers tidier formats, by setting the parameter tidy = TRUE the function returns a long-formated version of the results.
## func.pkg func.pkg.vers func.pkg.manual param.p param.method session.idx
## 1 stats 3.6.0 FALSE pval "bonferroni" 1
## 2 stats 3.6.0 FALSE pval "BH" 1
## 3 qvalue 2.17.0 FALSE pval <NA> 1
## 4 stats 3.6.0 FALSE pval "bonferroni" 1
## 5 stats 3.6.0 FALSE pval "BH" 1
## 6 qvalue 2.17.0 FALSE pval <NA> 1
## 7 stats 3.6.0 FALSE pval "bonferroni" 1
## 8 stats 3.6.0 FALSE pval "BH" 1
## 9 qvalue 2.17.0 FALSE pval <NA> 1
## pm.session label key value assay performanceMetric alpha
## 1 1 bonf TPR.1 0.125 H TPR 0.05
## 2 1 BH TPR.1 0.375 H TPR 0.05
## 3 1 qv TPR.1 0.600 H TPR 0.05
## 4 1 bonf TPR.2 0.200 H TPR 0.10
## 5 1 BH TPR.2 0.550 H TPR 0.10
## 6 1 qv TPR.2 0.700 H TPR 0.10
## 7 1 bonf TPR.3 0.225 H TPR 0.20
## 8 1 BH TPR.3 0.625 H TPR 0.20
## 9 1 qv TPR.3 0.900 H TPR 0.20As an alternative to get the same data.frame as the previous chunk, we can call the function tidyUpMetrics() on the saved results from a SummarizedBenchmark object.
## func.pkg func.pkg.vers func.pkg.manual param.p param.method session.idx
## 1 stats 3.6.0 FALSE pval "bonferroni" 1
## 2 stats 3.6.0 FALSE pval "BH" 1
## 3 qvalue 2.17.0 FALSE pval <NA> 1
## 4 stats 3.6.0 FALSE pval "bonferroni" 1
## 5 stats 3.6.0 FALSE pval "BH" 1
## 6 qvalue 2.17.0 FALSE pval <NA> 1
## pm.session label key value assay performanceMetric alpha
## 1 1 bonf TPR.1 0.125 H TPR 0.05
## 2 1 BH TPR.1 0.375 H TPR 0.05
## 3 1 qv TPR.1 0.600 H TPR 0.05
## 4 1 bonf TPR.2 0.200 H TPR 0.10
## 5 1 BH TPR.2 0.550 H TPR 0.10
## 6 1 qv TPR.2 0.700 H TPR 0.10For example, the code below extracts the TPR for an alpha of 0.1 for the Bonferroni method.
tidyUpMetrics(sb) %>%
dplyr:::filter(label == "bonf", alpha == 0.1, performanceMetric == "TPR") %>%
dplyr:::select(value)## value
## 1 0.2Next Steps
This vignette described the minimal structure of the SummarizedBenchmark framework using the BenchDesign and SummarizedBenchmark classes. This should be sufficient for building and executing simple benchmarks but may not be enough for more complex benchmarking experiments. A more detailed example using the SummarizedBenchmark is provided in the SummarizedBenchmark: Full Case Study vignette and additional features can be found the various Feature vignettes. A more complete description of the BenchDesign and SummarizedBenchmark classes can be found in the SummarizedBenchmark: Class Details vignette.
References
Benjamini, Yoav, and Yosef Hochberg. 1995. “Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing.” Journal of the Royal Statistical Society. Series B (Methodological), 289–300.
Dunn, Olive Jean. 1961. “Multiple Comparisons Among Means.” Journal of the American Statistical Association 56 (293):52–64.
Storey, John D. 2002. “A Direct Approach to False Discovery Rates.” Journal of the Royal Statistical Society: Series B (Statistical Methodology) 64 (3):479–98.